This document describes the current stable version of Celery (5.4). For development docs, go here.
Calling Tasks¶
Basics¶
This document describes Celery’s uniform “Calling API” used by task instances and the canvas.
The API defines a standard set of execution options, as well as three methods:
apply_async(args[, kwargs[, …]])Sends a task message.
delay(*args, **kwargs)Shortcut to send a task message, but doesn’t support execution options.
calling (
__call__)Applying an object supporting the calling API (e.g.,
add(2, 2)) means that the task will not be executed by a worker, but in the current process instead (a message won’t be sent).
Example¶
The delay() method is convenient as it looks like calling a regular
function:
task.delay(arg1, arg2, kwarg1='x', kwarg2='y')
Using apply_async() instead you have to write:
task.apply_async(args=[arg1, arg2], kwargs={'kwarg1': 'x', 'kwarg2': 'y'})
So delay is clearly convenient, but if you want to set additional execution
options you have to use apply_async.
The rest of this document will go into the task execution options in detail. All examples use a task called add, returning the sum of two arguments:
@app.task
def add(x, y):
return x + y
Linking (callbacks/errbacks)¶
Celery supports linking tasks together so that one task follows another. The callback task will be applied with the result of the parent task as a partial argument:
add.apply_async((2, 2), link=add.s(16))
Here the result of the first task (4) will be sent to a new
task that adds 16 to the previous result, forming the expression
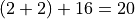
You can also cause a callback to be applied if task raises an exception (errback). The worker won’t actually call the errback as a task, but will instead call the errback function directly so that the raw request, exception and traceback objects can be passed to it.
This is an example error callback:
@app.task
def error_handler(request, exc, traceback):
print('Task {0} raised exception: {1!r}\n{2!r}'.format(
request.id, exc, traceback))
it can be added to the task using the link_error execution
option:
add.apply_async((2, 2), link_error=error_handler.s())
In addition, both the link and link_error options can be expressed
as a list:
add.apply_async((2, 2), link=[add.s(16), other_task.s()])
The callbacks/errbacks will then be called in order, and all callbacks will be called with the return value of the parent task as a partial argument.
In the case of a chord, we can handle errors using multiple handling strategies. See chord error handling for more information.
On message¶
Celery supports catching all states changes by setting on_message callback.
For example for long-running tasks to send task progress you can do something like this:
@app.task(bind=True)
def hello(self, a, b):
time.sleep(1)
self.update_state(state="PROGRESS", meta={'progress': 50})
time.sleep(1)
self.update_state(state="PROGRESS", meta={'progress': 90})
time.sleep(1)
return 'hello world: %i' % (a+b)
def on_raw_message(body):
print(body)
a, b = 1, 1
r = hello.apply_async(args=(a, b))
print(r.get(on_message=on_raw_message, propagate=False))
Will generate output like this:
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': {'progress': 50},
'children': [],
'status': 'PROGRESS',
'traceback': None}
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': {'progress': 90},
'children': [],
'status': 'PROGRESS',
'traceback': None}
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': 'hello world: 10',
'children': [],
'status': 'SUCCESS',
'traceback': None}
hello world: 10
ETA and Countdown¶
The ETA (estimated time of arrival) lets you set a specific date and time that is the earliest time at which your task will be executed. countdown is a shortcut to set ETA by seconds into the future.
>>> result = add.apply_async((2, 2), countdown=3)
>>> result.get() # this takes at least 3 seconds to return
4
The task is guaranteed to be executed at some time after the specified date and time, but not necessarily at that exact time. Possible reasons for broken deadlines may include many items waiting in the queue, or heavy network latency. To make sure your tasks are executed in a timely manner you should monitor the queue for congestion. Use Munin, or similar tools, to receive alerts, so appropriate action can be taken to ease the workload. See Munin.
While countdown is an integer, eta must be a datetime
object, specifying an exact date and time (including millisecond precision,
and timezone information):
>>> from datetime import datetime, timedelta, timezone
>>> tomorrow = datetime.now(timezone.utc) + timedelta(days=1)
>>> add.apply_async((2, 2), eta=tomorrow)
Warning
Tasks with eta or countdown are immediately fetched by the worker and until the scheduled time passes, they reside in the worker’s memory. When using those options to schedule lots of tasks for a distant future, those tasks may accumulate in the worker and make a significant impact on the RAM usage.
Moreover, tasks are not acknowledged until the worker starts executing them. If using Redis as a broker, task will get redelivered when countdown exceeds visibility_timeout (see Caveats).
Therefore, using eta and countdown is not recommended for scheduling tasks for a distant future. Ideally, use values no longer than several minutes. For longer durations, consider using database-backed periodic tasks, e.g. with https://pypi.org/project/django-celery-beat/ if using Django (see Using custom scheduler classes).
Warning
When using RabbitMQ as a message broker when specifying a countdown
over 15 minutes, you may encounter the problem that the worker terminates
with an PreconditionFailed error will be raised:
amqp.exceptions.PreconditionFailed: (0, 0): (406) PRECONDITION_FAILED - consumer ack timed out on channel
In RabbitMQ since version 3.8.15 the default value for
consumer_timeout is 15 minutes.
Since version 3.8.17 it was increased to 30 minutes. If a consumer does
not ack its delivery for more than the timeout value, its channel will be
closed with a PRECONDITION_FAILED channel exception.
See Delivery Acknowledgement Timeout for more information.
To solve the problem, in RabbitMQ configuration file rabbitmq.conf you
should specify the consumer_timeout parameter greater than or equal to
your countdown value. For example, you can specify a very large value
of consumer_timeout = 31622400000, which is equal to 1 year
in milliseconds, to avoid problems in the future.
Expiration¶
The expires argument defines an optional expiry time,
either as seconds after task publish, or a specific date and time using
datetime:
>>> # Task expires after one minute from now.
>>> add.apply_async((10, 10), expires=60)
>>> # Also supports datetime
>>> from datetime import datetime, timedelta, timezone
>>> add.apply_async((10, 10), kwargs,
... expires=datetime.now(timezone.utc) + timedelta(days=1))
When a worker receives an expired task it will mark
the task as REVOKED (TaskRevokedError).
Message Sending Retry¶
Celery will automatically retry sending messages in the event of connection failure, and retry behavior can be configured – like how often to retry, or a maximum number of retries – or disabled all together.
To disable retry you can set the retry execution option to False:
add.apply_async((2, 2), retry=False)
Retry Policy¶
A retry policy is a mapping that controls how retries behave, and can contain the following keys:
max_retries
Maximum number of retries before giving up, in this case the exception that caused the retry to fail will be raised.
A value of
Nonemeans it will retry forever.The default is to retry 3 times.
interval_start
Defines the number of seconds (float or integer) to wait between retries. Default is 0 (the first retry will be instantaneous).
interval_step
On each consecutive retry this number will be added to the retry delay (float or integer). Default is 0.2.
interval_max
Maximum number of seconds (float or integer) to wait between retries. Default is 0.2.
retry_errors
retry_errors is a tuple of exception classes that should be retried. It will be ignored if not specified. Default is None (ignored).
For example, if you want to retry only tasks that were timed out, you can use
TimeoutError:from kombu.exceptions import TimeoutError add.apply_async((2, 2), retry=True, retry_policy={ 'max_retries': 3, 'retry_errors': (TimeoutError, ), })
Added in version 5.3.
For example, the default policy correlates to:
add.apply_async((2, 2), retry=True, retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 0.2,
'retry_errors': None,
})
the maximum time spent retrying will be 0.4 seconds. It’s set relatively short by default because a connection failure could lead to a retry pile effect if the broker connection is down – For example, many web server processes waiting to retry, blocking other incoming requests.
Connection Error Handling¶
When you send a task and the message transport connection is lost, or
the connection cannot be initiated, an OperationalError
error will be raised:
>>> from proj.tasks import add
>>> add.delay(2, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "celery/app/task.py", line 388, in delay
return self.apply_async(args, kwargs)
File "celery/app/task.py", line 503, in apply_async
**options
File "celery/app/base.py", line 662, in send_task
amqp.send_task_message(P, name, message, **options)
File "celery/backends/rpc.py", line 275, in on_task_call
maybe_declare(self.binding(producer.channel), retry=True)
File "/opt/celery/kombu/kombu/messaging.py", line 204, in _get_channel
channel = self._channel = channel()
File "/opt/celery/py-amqp/amqp/connection.py", line 272, in connect
self.transport.connect()
File "/opt/celery/py-amqp/amqp/transport.py", line 100, in connect
self._connect(self.host, self.port, self.connect_timeout)
File "/opt/celery/py-amqp/amqp/transport.py", line 141, in _connect
self.sock.connect(sa)
kombu.exceptions.OperationalError: [Errno 61] Connection refused
If you have retries enabled this will only happen after retries are exhausted, or when disabled immediately.
You can handle this error too:
>>> from celery.utils.log import get_logger
>>> logger = get_logger(__name__)
>>> try:
... add.delay(2, 2)
... except add.OperationalError as exc:
... logger.exception('Sending task raised: %r', exc)
Serializers¶
Data transferred between clients and workers needs to be serialized,
so every message in Celery has a content_type header that
describes the serialization method used to encode it.
The default serializer is JSON, but you can
change this using the task_serializer setting,
or for each individual task, or even per message.
There’s built-in support for JSON, pickle, YAML
and msgpack, and you can also add your own custom serializers by registering
them into the Kombu serializer registry
See also
Message Serialization in the Kombu user guide.
Each option has its advantages and disadvantages.
- json – JSON is supported in many programming languages, is now
a standard part of Python (since 2.6), and is fairly fast to decode.
The primary disadvantage to JSON is that it limits you to the following data types: strings, Unicode, floats, Boolean, dictionaries, and lists. Decimals and dates are notably missing.
Binary data will be transferred using Base64 encoding, increasing the size of the transferred data by 34% compared to an encoding format where native binary types are supported.
However, if your data fits inside the above constraints and you need cross-language support, the default setting of JSON is probably your best choice.
See http://json.org for more information.
Note
(From Python official docs https://docs.python.org/3.6/library/json.html) Keys in key/value pairs of JSON are always of the type
str. When a dictionary is converted into JSON, all the keys of the dictionary are coerced to strings. As a result of this, if a dictionary is converted into JSON and then back into a dictionary, the dictionary may not equal the original one. That is,loads(dumps(x)) != xif x has non-string keys.- pickle – If you have no desire to support any language other than
Python, then using the pickle encoding will gain you the support of all built-in Python data types (except class instances), smaller messages when sending binary files, and a slight speedup over JSON processing.
See
picklefor more information.- yaml – YAML has many of the same characteristics as json,
except that it natively supports more data types (including dates, recursive references, etc.).
However, the Python libraries for YAML are a good bit slower than the libraries for JSON.
If you need a more expressive set of data types and need to maintain cross-language compatibility, then YAML may be a better fit than the above.
To use it, install Celery with:
$ pip install celery[yaml]
See http://yaml.org/ for more information.
- msgpack – msgpack is a binary serialization format that’s closer to JSON
in features. The format compresses better, so is a faster to parse and encode compared to JSON.
To use it, install Celery with:
$ pip install celery[msgpack]
See http://msgpack.org/ for more information.
To use a custom serializer you need to add the content type to
accept_content. By default, only JSON is accepted,
and tasks containing other content headers are rejected.
The following order is used to decide the serializer used when sending a task:
The serializer execution option.
The
Task.serializerattributeThe
task_serializersetting.
Example setting a custom serializer for a single task invocation:
>>> add.apply_async((10, 10), serializer='json')
Compression¶
Celery can compress messages using the following builtin schemes:
brotli
brotli is optimized for the web, in particular small text documents. It is most effective for serving static content such as fonts and html pages.
To use it, install Celery with:
$ pip install celery[brotli]
bzip2
bzip2 creates smaller files than gzip, but compression and decompression speeds are noticeably slower than those of gzip.
To use it, please ensure your Python executable was compiled with bzip2 support.
If you get the following
ImportError:>>> import bz2 Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named 'bz2'
it means that you should recompile your Python version with bzip2 support.
gzip
gzip is suitable for systems that require a small memory footprint, making it ideal for systems with limited memory. It is often used to generate files with the “.tar.gz” extension.
To use it, please ensure your Python executable was compiled with gzip support.
If you get the following
ImportError:>>> import gzip Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named 'gzip'
it means that you should recompile your Python version with gzip support.
lzma
lzma provides a good compression ratio and executes with fast compression and decompression speeds at the expense of higher memory usage.
To use it, please ensure your Python executable was compiled with lzma support and that your Python version is 3.3 and above.
If you get the following
ImportError:>>> import lzma Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named 'lzma'
it means that you should recompile your Python version with lzma support.
Alternatively, you can also install a backport using:
$ pip install celery[lzma]
zlib
zlib is an abstraction of the Deflate algorithm in library form which includes support both for the gzip file format and a lightweight stream format in its API. It is a crucial component of many software systems - Linux kernel and Git VCS just to name a few.
To use it, please ensure your Python executable was compiled with zlib support.
If you get the following
ImportError:>>> import zlib Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named 'zlib'
it means that you should recompile your Python version with zlib support.
zstd
zstd targets real-time compression scenarios at zlib-level and better compression ratios. It’s backed by a very fast entropy stage, provided by Huff0 and FSE library.
To use it, install Celery with:
$ pip install celery[zstd]
You can also create your own compression schemes and register
them in the kombu compression registry.
The following order is used to decide the compression scheme used when sending a task:
The compression execution option.
The
Task.compressionattribute.The
task_compressionattribute.
Example specifying the compression used when calling a task:
>>> add.apply_async((2, 2), compression='zlib')
Connections¶
You can handle the connection manually by creating a publisher:
numbers = [(2, 2), (4, 4), (8, 8), (16, 16)]
results = []
with add.app.pool.acquire(block=True) as connection:
with add.get_publisher(connection) as publisher:
try:
for i, j in numbers:
res = add.apply_async((i, j), publisher=publisher)
results.append(res)
print([res.get() for res in results])
Though this particular example is much better expressed as a group:
>>> from celery import group
>>> numbers = [(2, 2), (4, 4), (8, 8), (16, 16)]
>>> res = group(add.s(i, j) for i, j in numbers).apply_async()
>>> res.get()
[4, 8, 16, 32]
Routing options¶
Celery can route tasks to different queues.
Simple routing (name <-> name) is accomplished using the queue option:
add.apply_async(queue='priority.high')
You can then assign workers to the priority.high queue by using
the workers -Q argument:
$ celery -A proj worker -l INFO -Q celery,priority.high
See also
Hard-coding queue names in code isn’t recommended, the best practice
is to use configuration routers (task_routes).
To find out more about routing, please see Routing Tasks.
Results options¶
You can enable or disable result storage using the task_ignore_result
setting or by using the ignore_result option:
>>> result = add.apply_async((1, 2), ignore_result=True)
>>> result.get()
None
>>> # Do not ignore result (default)
...
>>> result = add.apply_async((1, 2), ignore_result=False)
>>> result.get()
3
If you’d like to store additional metadata about the task in the result backend
set the result_extended setting to True.
See also
For more information on tasks, please see Tasks.
Advanced Options¶
These options are for advanced users who want to take use of AMQP’s full routing capabilities. Interested parties may read the routing guide.
exchange
Name of exchange (or a
kombu.entity.Exchange) to send the message to.routing_key
Routing key used to determine.
priority
A number between 0 and 255, where 255 is the highest priority.
Supported by: RabbitMQ, Redis (priority reversed, 0 is highest).

