CEP XXXX: Celery 5 High Level Architecture¶
- CEP
XXXX
- Author
Omer Katz
- Implementation Team
Omer Katz
- Shepherd
Omer Katz
- Status
Draft
- Type
Informational
- Created
2019-04-08
- Last-Modified
2019-04-08
Table of Contents
Abstract¶
When Celery was conceived, production environments were radically different from today.
Nowadays most applications are (or should be):
Deployed to a cloud provider’s computing resources.
Distributed (sometimes between data centers).
Available or Consistent (We must pick one according to CAP Theorem).
Network Partition Tolerant.
Observable.
Built with scalability in mind.
Cloud Native - The application’s lifecycle is managed using Kubernetes, Swarm or any other scheduler.
In addition, Celery lacks proper support for large scale deployments and some useful messaging architectural patterns.
Celery 5 is the next major version of Celery and so we are able to break backwards compatibility, even in major ways.
As such, our next major version should represent a paradigm shift in the way we implement our task execution platform.
Specification¶
Note
The code examples below are for illustration purposes only.
Unless explicitly specified, The API will be determined in other CEPs.
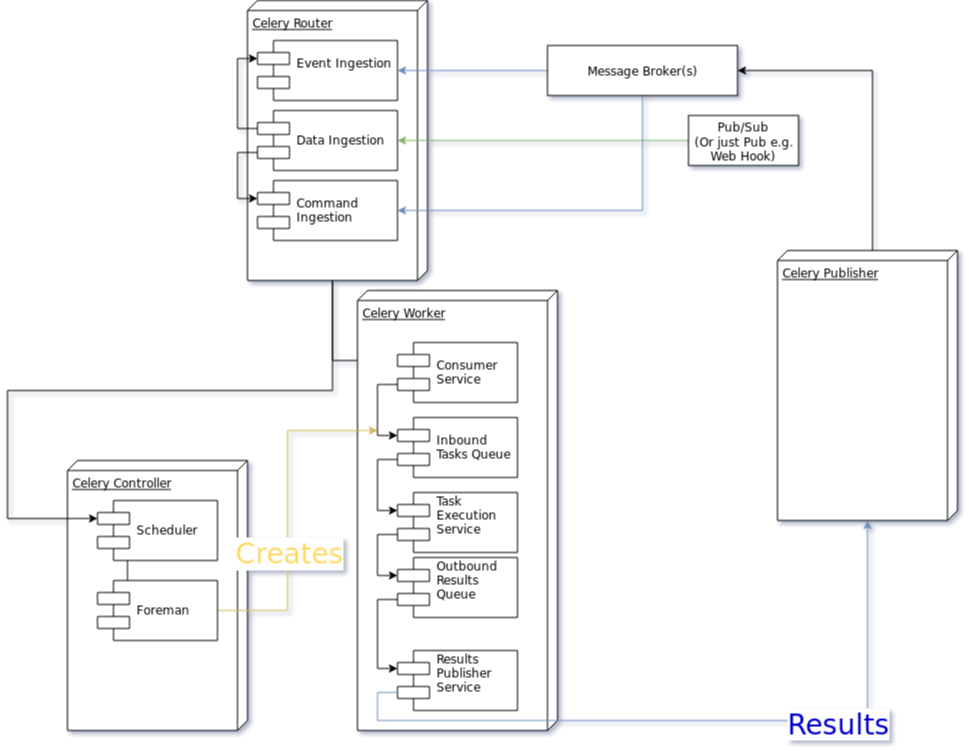
High Level Architecture Diagram¶
Message Types¶
In relation to Celery Command messages are the messages we publish to the Message Broker whenever we want to execute a Task.
Document messages are the messages we get as a result.
Document messages may also be produced whenever we publish a serialized representation of a Domain Model.
>>> from celery import task
>>> @task
... def add(a, b):
... return a + b
>>> result = add.delay(1, 2) # Publish a command message
>>> result.get() # Consume a Document message
3
Event messages are a new concept for Celery. They describe that a Domain Event occurred. Multiple tasks can be subscribed to an event.
>>> from uuid import UUID
>>> from celery import task, event
>>> from myapp.models import User, AccountManager
>>> @task
... def send_welcome_email(user_id, email):
... send_email(email=email, contents="hello, welcome", subject="welcome") # Send a welcome email to the user...
... User.objects.filter(pk=user_id).update(welcome_email_sent=True)
>>> @task
... def notify_account_manager(user_id, email):
... account_manager = AccountManager.objects.assign_account_manager(user_id)
... send_email(email=account_manager.email, contents="you have a new user to attend to", subject="Alert") # Send an email to the account manager...
>>> @event
... class UserRegistered:
... user_id: UUID
... email: str
>>> UserRegistered.subscribe(send_welcome_email)
>>> UserRegistered.subscribe(notify_account_manager)
>>> UserRegistered.delay(user_id=1, email='foo@bar.com') # Calls both send_welcome_email and notify_account_manager with the provided arguments.
These architectural building blocks will aid us in creating a better messaging system. To encourage Ubiquitous Language, we will be using them in this document and in Celery 5’s codebase as well.
Message Passing Protocol¶
In previous versions of Celery the only protocol we defined was for the message format itself.
Whenever a client published a message to the broker using task.delay() Celery serialized it to a known format which it can use to invoke the task remotely.
This meant that you needed a special client library to publish tasks that Celery will later consume and execute. The architectural implication is a coupling between the publisher and the consumer which defeats the general use-case of message passing: decoupling the publisher from the consumer.
In addition, the communication protocol between the master process and the workers was an internal implementation detail which was not well defined or understood by the maintainers or users.
Introduction to AMQP 1.0 Terminology¶
AMQP 1.0 is a flexible messaging protocol that is designed to pass messages between nodes. Nodes can be queues, exchanges, Kafka-like log stream or any other entity which which publishes or consumes a message from another node.
AMQP 1.0, unlike AMQP 0.9.1, does not mandate the presence of a broker to facilitate message passing.
This feature allows us to use it to communicate effectively between the different Celery components without overloading the broker with connections and messages. It also allows users to invoke tasks directly without the usage of a Message Broker, thus treating a Worker as an actor.
Connections¶
Sessions¶
Channels¶
Nodes (Components)¶
Nodes (also called Components) are entities on either different processes which establish links.
Links¶
Terminus¶
Implementation¶
The python bindings to the qpid-proton library exposes all these features, can be used with trio and is supported on PyPy.
We will use it as a fundamental building block for our entire architecture.
Canvas¶
In Celery Canvas is the mechanism which users can use to define workflows dynamically.
In previous versions of Celery there are issues with the protocol which can cause Celery to generate messages too large for storage in Message Brokers. There are also issues with the API and multiple implementation problems.
In Celery 5 we’re going to revamp the protocol, API and possibly the implementation itself to resolve these issues.
Signatures¶
Primitives¶
Error Handling¶
Error Recovery¶
Chains¶
Groups¶
Chords¶
Maps¶
Starmaps¶
Chunks¶
Forks¶
Workflows¶
A Workflow is a declarative Canvas.
Workflows provide an API for incrementally executing business logic by dividing it to small, self-contained tasks.
Unlike Canvas, a Workflow is immutable, static and predicable.
Observability¶
One of Celery 5’s goals is to be observable.
Each Celery component will record statistics, provide trace points for application monitoring tools and distributed tracing tools and emit log messages when appropriate.
Metrics¶
Celery stores and publishes metrics which allows our users to debug their applications more easily and spot problems.
By default each worker will publish the metrics to a dedicated queue.
Other methods such as publishing them to StatsD is also possible using the provided extension point.
Trace Points¶
Celery provides trace points for application monitoring tools and distributed tracing tools.
This allows our users to spot and debug performance issues.
Logging¶
All log messages must be structured. Structured logs provide context for our users which allows them to debug problems more easily and aids the developers to resolve bugs in Celery.
The structure of a log message is determined whenever a component is initialized.
During initialization, an attempt will be made to detect how the component lifecycle is managed. If all attempts are unsuccessful, the logs will be formatted using JSON and will be printed to stdout.
Celery will provide an extension point for detection of different runtimes.
Example
If a component’s lifecycle is managed by a SystemD service, Celery will detect that the JOURNAL_STREAM environment variable is set when the process starts and use it’s value to transmit structured data into journald.
Whenever Celery fails to log a message for any reason it publishes a command to the worker’s Inbox Queue in order to log the message again. As usual messages which fail to be published are stored in the Messages Backlog.
In past versions of Celery we’ve used the standard logging module. Unfortunately it does not meet the aforementioned requirements.
Eliot is a logging library which provides structure and context to logs, even across coroutines, threads and processes.
It is also able to emit logs to journald and has native trio integration.
Network Resilience and Fault Tolerance¶
Celery 5 aims to be network failure resilient and fault tolerant. As an architectural guideline Celery must retry operations by default and must avoid doing so indefinitely and without proper limits.
Any operation which cannot be executed either momentarily or permanently as a result of a bug must not be retried beyond the configured limits. Instead, Celery must store the operation for further inspection and if required, manual intervention.
Celery must track and automatically handle “poisonous messages” to ensure the recovery of the Celery cluster.
Fault Tolerance¶
Distributed Systems suffer from an inherent property:
Any distributed system is unreliable.
The network may be unavailable or slow.
Some or all of the servers might suffer from a hardware failure.
A node in the system may arbitrarily crash due to lack of memory or a bug.
Any number of unaccounted failure modes.
Therefore, Celery must be fault tolerant and gracefully degrade its’ operation when failures occur.
Graceful Degradation¶
Features which are less mission-critical may fail at any time, provided that a warning is logged.
This document will highlight such features and describe what happens when they fail for any reason.
Retries¶
In previous Celery versions tasks were not retried by default.
This forces new adopters to carefully read our documentation to ensure the fault tolerance of their tasks.
In addition, our retry policy was declared at the task level. When using Automatic retry for known exceptions Celery automatically retries tasks when specific exceptions are raised.
However the same type of exception may hold a different meaning in different contexts.
This created the following pattern:
from celery import task
from data_validation_lib import validate_data
def _calculate(a, b):
# Do something
@task(autoretry_for=(ValueError,))
def complex_calculation(a, b):
try:
# Code that you don't control can raise a ValueError.
validate_data(a, b)
except ValueError:
print("Complete failure!")
return
# May temporarily raise a ValueError due to some externally fetched
# data which is currently incorrect but will be updated later.
_calculate()
An obvious way around this problem is to ensure that _calculate() raises a custom exception.
But we shouldn’t force the users to use workarounds. Our code should be ergonomic and idiomatic.
Instead, we should allow users to declare sections as “poisonous” - tasks that if retried will surely fail if they fail at those sections.
from celery import task, poisonous
from data_validation_lib import validate_data
def _calculate(a, b):
# Do something
@task(autoretry_for=(ValueError,))
def complex_calculation(a, b):
with poisonous():
validate_data(a, b)
# May temporarily raise a ValueError due to some externally fetched
# data which is currently incorrect but will be updated later.
_calculate()
Not all operations are equal. Some may be retried more than others. Some may need to be retried less often.
Currently there are multiple ways to achieve this:
You can separate them to different tasks with a different retry policy:
from celery import task
@task(retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 0.2
})
def foo():
second_operation()
@task(retry_policy={
'max_retries': 10,
'interval_start': 0,
'interval_step': 5,
'interval_max': 120
})
def bar():
first_operation()
foo.delay()
Or you can wrap each code section in a try..except clause and call
celery.app.task.Task.retry().
@task(bind=True)
def foo(self):
try:
# first operation
except Exception:
self.retry(retry_policy={
'max_retries': 10,
'interval_start': 0,
'interval_step': 5,
'interval_max': 120
})
try:
first_operation()
except Exception:
self.retry(retry_policy={
'max_retries': 10,
'interval_start': 0,
'interval_step': 5,
'interval_max': 120
})
try:
second_operation()
except Exception:
self.retry(retry_policy={
'max_retries': 3,
'interval_start': 0,
'interval_step': 0.2,
'interval_max': 1
})
Those solutions are unnecessarily verbose. Instead, we could use a with clause if all we want to do is retry.
@task
def foo():
with retry(max_retries=10, interval_start=0, interval_step=5, interval_max=120):
first_operation()
with retry(max_retries=3, interval_start=0, interval_step=0.2, interval_max=1):
second_operation()
By default messages which cannot be re-published will be stored in the Messages Backlog.
Implementers may provide other fallbacks such as executing the retried task in the same worker or abandoning the task entirely.
Some operations are not important enough to be retried if they fail.
Example
We’re implementing a BI system that records mouse interactions.
The BI team has specified that it wants to store the raw data and the time span between interactions. Since we have a lot of data already, if the system failed to insert the raw data into the data store then we should not fail. Instead, we should emit a warning. However, the time span between mouse interactions is critical to the BI team’s insight and if that fails to be inserted into the data store we must retry it.
Such a task can be defined using the optional context manager.
@task
def foo(raw_data):
# Using default retry policy
with optional():
# ignore retry policy and proceed
insert_raw_data(raw_data)
with retry(max_retries=10, interval_start=0, interval_step=5, interval_max=120):
calculation = time_span_calculation(raw_data)
insert_time_spans(calculation)
In case of a failure inside the optional context manager, a warning is logged.
We can of course be more specific about the failures we allow:
@task
def foo(raw_data):
# Using default retry policy
with optional(ConnectionError, TimeoutError):
# ignore retry policy and proceed
insert_raw_data(raw_data)
with retry(max_retries=10, interval_start=0, interval_step=5, interval_max=120):
calculation = time_span_calculation(raw_data)
insert_time_spans(calculation)
Health Checks¶
Health Checks are used in Celery to verify that a worker is able to successfully execute a task or a service.
The Scheduler is responsible for scheduling the health checks for execution in each worker after each time the configured period of time lapses.
Whenever a health check should be executed the Scheduler instructs the Publisher to send the <health check name>_expired Event Message to each worker’s Inbox Queue.
Workers which have tasks subscribed to the event will execute all the subscribed tasks in order to determine the state of the health check.
Health Checks can handle Document Messages as input from Data Sources.
This is useful when you want to respond to an alert from a monitoring system or when you want to verify that all incoming data from said source is valid at all times before executing the task.
In addition to tasks, Health Checks can also use Services in order to track changes in the environment it is running on.
Example
We have a task which requires 8GB of memory to complete. The worker runs a service which constantly monitors the system’s available memory. If there is not enough memory it changes the task’s health check to the Unhealthy state.
If a task or a service that is part of a health check fails unexpectedly it is ignored and an error message is logged.
Celery provides many types of health checks in order to verify that it can operate without any issues.
Users may implement their own health checks in addition to the built-in health checks.
Some health checks are specific to the worker they are executing on. Therefore, their state is stored in-memory in the worker.
Other health checks are global to all or a group of workers. As such, their state is stored externally.
If the state storage for health checks is not provided, these health checks are disabled.
Health Checks can be associated with tasks in order to ensure that they are likely to succeed. Multiple Health Check failures may trigger a Circuit Breaker which will prevent the task from running for a period of time or automatically mark it as failed.
Each Health Check declares its possible states. Sometimes it makes sense to try to execute a task anyway even if the health check occasionally fails.
Example
A health check that verifies whether we can send a HTTP request to an endpoint has multiple states.
The health check performs an OPTIONS HTTP request to that endpoint and expects it to respond within the specified timeout.
The health check is in a Healthy state if all the following conditions are met:
The DNS server is responding within the specified time limit and is resolving the address correctly.
The TLS certificates are valid and the connection is secure.
The Intrusion Detection System reports that the network is secure.
The HTTP method we’re about to use is listed in the OPTIONS response’s ALLOW header.
The content type we’re about to format the request in is listed in the OPTIONS response’s ACCEPT header.
The OPTIONS request responds within the specified time limits.
The OPTIONS request responds with 200 OK status.
In addition, the actual request performed in the task must also stand in the aforementioned conditions. Otherwise, the health check will change it’s state.
The health check can be in an Insecure state if one or more of the following conditions are met:
The TLS certificates are invalid for any reason.
The Intrusion Detection System has reported that the network is compromised for any reason.
It is up for the user to configure the Circuit Breaker to prevent insecure requests from being executed.
The health check can be in an Degraded state if one or more of the following conditions are met:
The request does not reply with a 2xx HTTP status.
The request responds slowly and almost reaches it’s time limits.
It is up for the user to configure the Circuit Breaker to prevent requests from being executed after multiple attempts or not all.
The health check can be in an Unhealthy state if one or more of the following conditions are met:
The request responds with a 500 HTTP status.
The request’s response has not been received within the specified time limits.
It is up for the user to configure the Circuit Breaker to prevent requests from being executed if there is an issue with the endpoint.
The health check can be in an Permanently Unavailable state if one or more of the following conditions are met:
The request responds with a 404 Not Found HTTP status.
The HTTP method we’re about to use is not allowed.
The content type we’re about to use is not allowed.
Circuit Breaking¶
Celery 5 introduces the concept of Circuit Breaker into the framework.
A Circuit Breaker prevents a task or a service from executing.
Each task or a service has a Circuit Breaker which the user can associate health checks with.
In addition, if the task or the service unexpectedly fails, the user can configure the Circuit Breaker to trip after a configured number of times. The default value is 3 times.
Whenever a Circuit Breaker trips, the worker will emit a warning log message.
After a configured period of time the circuit is opened again and tasks may execute. The default period of time is 30 seconds with no linear or exponential growth.
The user will configure the following properties of the Circuit Breaker:
How many times the health checks may fail before the circuit breaker trips.
How many unexpected failures the task or service tolerates before tripping the Circuit Breaker.
The period of time after which the circuit is yet again closed. That time period may grow linearly or exponentially.
How many circuit breaker trips during a period of time should cause the worker to produce an error log message instead of a warning log message.
The period of time after which the circuit breaker downgrades it’s log level back to warning.
Example
We allow 2 Unhealthy health checks and/or 10 Degraded health checks in a period of 10 seconds.
If we cross that threshold, the circuit breaker trips.
The circuit will be closed again after 30 seconds. Afterwards, the task can be executed again.
If 3 consequent circuit breaker trips occurred during a period of 5 minutes, all circuit breaker trips will emit an error log message instead of a warning.
The circuit breaker will downgrade it’s log level after 30 minutes.
Network Resilience¶
Network Connections may fail at any time. In order to be network resilient we must use retries and circuit breakers on all outgoing and incoming network connections.
In addition, proper timeouts must be set to avoid hanging when the connection is slow or unresponsive.
Each network connection must be accompanied by a health check.
Health check failures must eventually trip a circuit breaker.
Command Line Interface¶
Our command line interface is the user interface to all of Celery’s functionality. It is crucial for us to provide an excellent user experience.
Currently Celery uses argparse with a few custom hacks and workarounds for
things which are not possible to do with argparse.
This created some bugs in the past.
Celery 5 will use Click, a modern Python library for creating command line programs.
Click’s documentation explains why it is a good fit for us:
There are so many libraries out there for writing command line utilities; why does Click exist?
This question is easy to answer: because there is not a single command line utility for Python out there which ticks the following boxes:
is lazily composable without restrictions
supports implementation of Unix/POSIX command line conventions
supports loading values from environment variables out of the box
supports for prompting of custom values
is fully nestable and composable
works the same in Python 2 and 3
supports file handling out of the box
comes with useful common helpers (getting terminal dimensions, ANSI colors, fetching direct keyboard input, screen clearing, finding config paths, launching apps and editors, etc.)
There are many alternatives to Click and you can have a look at them if you enjoy them better. The obvious ones are
optparseandargparsefrom the standard library.Click actually implements its own parsing of arguments and does not use
optparseorargparsefollowing theoptparseparsing behavior. The reason it’s not based onargparseis thatargparsedoes not allow proper nesting of commands by design and has some deficiencies when it comes to POSIX compliant argument handling.Click is designed to be fun to work with and at the same time not stand in your way. It’s not overly flexible either. Currently, for instance, it does not allow you to customize the help pages too much. This is intentional because Click is designed to allow you to nest command line utilities. The idea is that you can have a system that works together with another system by tacking two Click instances together and they will continue working as they should.
Too much customizability would break this promise.
Click describes it’s advantages over argparse in its documentation as well:
Click is internally based on optparse instead of argparse. This however is an implementation detail that a user does not have to be concerned with. The reason however Click is not using argparse is that it has some problematic behaviors that make handling arbitrary command line interfaces hard:
argparse has built-in magic behavior to guess if something is an argument or an option. This becomes a problem when dealing with incomplete command lines as it’s not possible to know without having a full understanding of the command line how the parser is going to behave. This goes against Click’s ambitions of dispatching to subparsers.
argparse currently does not support disabling of interspersed arguments. Without this feature it’s not possible to safely implement Click’s nested parsing nature.
In contrast to argparse, the Click community
provides many extensions we can use to create a better user experience
for our users.
Click supports calling async methods and functions using the asyncclick <https://github.com/python-trio/asyncclick>`_ fork which is likely to be important for us in the future.
Dependency Inversion¶
Currently Celery uses different singleton registries to customize the behavior of its’ different components. This is known as the Service Locator pattern.
Mark Seemann criticized Service Locators as an anti-pattern for multiple reasons:
Using constructor injection is a much better way to invert our dependencies.
For that purpose we have selected the dependencies library.
Worker¶
The Worker is the most fundamental architectural component in Celery.
The role of the Worker is to be a Service Activator. It executes Tasks in response to messages.
A Worker is also an Idempotent Receiver. If the exact same Message is received more than once, the duplicated messages are discarded. In this case, a warning log message is emitted. The Worker maintains a list of identifiers of recently received messages. The number of messages is determined by a configuration value. By default that value is 100 messages.
Configuration¶
In previous versions of Celery we had the option to load the configuration from a Python module.
Cloud Native applications often use Etcd, Consul or Kubernetes Config Maps (among others) to store configuration and adjust it when needed.
Celery 5 introduces the concept of configuration backends. These backends allow you to load the Worker’s configuration from any source.
The default configuration backend loads the configuration from a Python module.
Users may create their own configuration backends to load configuration from a YAML file, a TOML file or a database.
Once the configuration has changed, the Worker stops consuming tasks, waits for all other tasks to finish and reloads the configuration.
This behavior can be disabled using a CLI option.
Event Loop¶
In Celery 4 we have implemented our own custom Event Loop. It is a cause for many bugs and issues in Celery.
In addition, some I/O operations are still blocking the event loop since the clients we use do not allow non-blocking operations.
The most important feature of Celery 5 is to replace the custom Event Loop with Trio.
We selected it because of its design, interoperability with asyncio and its many features.
Trio provides a context manager which limits the concurrency of coroutines and/or threads. This saves us from further bookkeeping when a Worker executes Tasks.
Trio allows coroutines to report their status. This is especially useful when we want to block the execution of other coroutines until initialization of the coroutine completes. We require this feature for implementing Boot Steps.
Trio also provides a feature called cancellation scopes which allows us to cancel a coroutine or multiple coroutines at once. This allows us to abort Tasks and handle the aborted tasks in an idiomatic fashion.
All of those features save us from writing a lot of code. If we were to select asyncio as our Event Loop, we’d have to implement most of those features ourselves.
Internal Tasks Queue¶
The internal tasks queue is an in-memory queue which the worker uses to queue tasks for execution.
Each task type has its own queue.
The queue must be thread-safe and coroutine-safe.
Internal Results Queue¶
The internal results queue is an in-memory queue which the worker uses to report the result of tasks back to the Router.
The queue must be thread-safe and coroutine-safe.
Services¶
Services are stateful, long running tasks which are used by Celery to perform its internal operations.
Some services publish messages to brokers, others consume messages from them. Other services are used to calculate optimal scheduling of tasks, routing, logging and even executing tasks.
Users may create their own services as well.
Internal Services¶
The Worker defines internal services to ensure it’s operation and to provide support for it’s features.
The exact API for each service will be determined in another CEP.
This list of internal services is not final. Other internal services may be defined in other CEPs.
Task Execution¶
The Task Execution service is responsible for executing all Celery
tasks.
It consumes tasks from the Internal Tasks Queue, executes them and enqueues the results into the Internal Results Queue.
The service supervises how many tasks are run concurrently and limits the number of concurrent tasks to the configured amount in accordance to the Concurrency Budget.
The service also attempts to saturate all of the available resources by scheduling as many as I/O Bound Tasks and CPU Bound Tasks as possible.
Consumer¶
The Consumer service consumes messages from one or many
Routers or
Message Brokers.
The service enqueues the consumed messages into the appropriate Internal Tasks Queue according to the task’s type.
Result Publisher¶
The Result Publisher service consumes results from the
Internal Results Queue and
publishes them to the Router’s
Inbox Queue.
Maximal Concurrency Budget¶
The Maximal Concurrency Budget service runs the user’s concurrency budget
strategies and notifies the tasks
service of changes in concurrency.
Tasks¶
Tasks are short running, have a defined purpose and are triggered in response to messages.
Celery declares some tasks for internal usage.
Users will create their own tasks for their own use.
Deduplication¶
Some Tasks are not idempotent and may not run more than once.
Users may define a deduplication policy to help Celery discard duplicated messages.
Example
The send_welcome_email task is only allowed to send one welcome email per
user.
The user defines a deduplication policy which checks with their 3rd party email delivery provider if that email has already been sent. If it did, the user instructs Celery to reject the task.
I/O Bound Tasks¶
I/O bound tasks are tasks which mainly perform a network operation or a disk operation.
I/O bound tasks are specifically marked as such using Python’s async def notation for defining awaitable functions. They will run in a Python coroutine.
Due to that, any I/O operation in that task must be asynchronous in order to avoid blocking the event loop.
Some of the user’s asynchronous tasks won’t use trio as their event loop but will use the more commonly used asyncio event loop which we do support.
In that case, the user must specify the event loop they are going to use for the task.
CPU Bound Tasks¶
CPU bound tasks are tasks which mainly perform a calculation of some sort such as calculating an average, hashing, serialization or deserialization, compression or decompression, encryption or decryption etc. In some cases where no asynchronous code for the I/O operation is available CPU bound tasks are also an appropriate choice as they will not block the event loop for the duration of the task.
Performing operations which release the GIL is recommended to avoid throttling the concurrency of the worker.
CPU bound tasks are specifically marked as such using Python’s def notation for defining functions. They will run in a Python thread.
Using threads instead of forking the main process has its upsides:
It simplifies the Worker’s architecture and makes it less brittle.
Processes require IPC to communicate with each other. This complicates implementation since multiple methods are required to support IPC reliably across all operating systems Celery supports. Threads on the other hand require less complicated means of communication.
In trio, we simply use a memory channel which is a coroutine and thread safe way to send and receive values.
PyPy’s JIT warms up faster.
When using PyPy, using threads means that we get to keep our previous JIT traces and therefore JIT warmup will occur faster.
If we’d use processes, each process has to warm up its own JIT which results in tasks being executed slower for a longer period of time.
Using threads for CPU bound tasks unfortunately has some downsides as well:
Pure Python CPU bound workloads cannot be executed in parallel.
In both CPython and PyPy the GIL prevents executing two Python bytecodes in parallel by design.
This results in slower execution of Python code when using threads.
The GIL’s implementation in CPython 3.x has a defect in design.
According to a bug report the new GIL in Python 3 CPU bound threads may starve I/O threads (in our case the main thread).
Note
This is not an issue with PyPy’s implementation of the GIL according to Armin Rigo, PyPy’s creator.
Tasks are no longer isolated.
Since we’re mixing workloads to maximize our throughput a task which crashes the worker or leaks memory can crash the entire worker.
To mitigate these issues CPU Bound Tasks may be globally rate limited to allow the main thread to complete executing I/O Bound Tasks.
Boxed Tasks¶
To minimize the disadvantages of using threads in Python and workaround the shortcomings of the GIL, Celery also provides a new type of tasks called Boxed Tasks.
Boxed Tasks are processes which execute tasks in an isolated manner.
The processes’ lifecycle is managed by the Controller.
Since Boxed Tasks are run separately from Celery itself, the program the process is running can be written in any language as long as it implements IPC in the same way the Controller expects.
Boxed tasks are a special kind of I/O Bound Tasks. They are executed the same way inside the worker but defined using a different API.
Concurrency Budget¶
Each worker has a concurrency budget for each type of task it can run.
The budget for each type of task is defined by a minimal and an optional maximal concurrency.
The maximal concurrency budget can be dynamic or fixed. Dynamic maximal concurrency strategies may be used to determine the maximum concurrency based on the load factor of the server, available network bandwidth or any other requirement the user may have.
Note
If a user specifies a concurrency of more than 10 for CPU Bound Tasks a warning log message is emitted.
Too many threads can cause task execution to grind down to a halt.
If there are more tasks in the Internal Tasks Queue than what is currently the allowed maximum task concurrency we increase the current maximum by that number of tasks. After this increase, there will be a configurable cooldown period during which the worker will execute the new tasks. After the cooldown period, if there are still more tasks in the Internal Tasks Queue than the current maximum capacity we increase the maximum concurrency exponentially by a configurable exponent multiplied by the number of budget increases. The result is rounded up.
This process goes on until we either reach the maximum concurrency budget for that type of tasks or if the number of tasks in Internal Tasks Queue is lower than the current maximum concurrency.
If the current number of tasks is lower than the current maximal concurrency we decrease it to the number of tasks that are currently executing.
This algorithm can be replaced or customized by the user.
Internal Tasks¶
Celery defines internal tasks to ensure it’s operation and to provide support for it’s features.
The exact API for each task will be determined in another CEP.
This list of internal tasks is not final. Other internal tasks may be defined in other CEPs.
SystemD Notify¶
This task reports the status of the worker to the SystemD service which is running it.
It uses the sd_notify protocol to do so.
Retry Failed Boot Step¶
This task responds to a Command Message which instructs the worker to retry an optional Boot Step which has failed during the worker’s initialization procedure.
The Boot Step’s execution will be retried a configured amount of times before giving up.
By default this task’s Circuit Breaker is configured to never prevent or automatically fail the execution of this task.
Boot Steps¶
During the Worker’s initialization procedure Boot Steps are executed to prepare it for execution of tasks.
Some Boot Steps are responsible for starting all the services required for the worker to function correctly. Others may publish a task for execution to the worker’s Inbox Queue.
Some Boot Steps are mandatory and thus if they fail, the worker refuses to start. Others are optional and their execution will be deferred to the Retry Failed Boot Step task.
Users may create and use their own Boot Steps if they wish to do so.
Worker Health Checks¶
Worker Circuit Breakers¶
Inbox Queue¶
Each worker declares an inbox queue in the Message Broker.
Publishers may publish messages to that queue in order to execute tasks on a specific worker.
Celery uses the Inbox Queue to schedule the execution of the worker’s internal tasks.
Messages published to the inbox queue must be cryptographically signed.
This requirement can be disabled using a CLI option. Whenever the user uses this CLI option a warning log message is emitted.
While disabling the inbox queue is possible either through a configuration setting or a CLI option, some functionality will be lost. Whenever the user opts to disable the Inbox Queue a warning log message is emitted.
Publisher¶
The Publisher is responsible for publishing messages to a Message Broker.
It is responsible for publishing the Message to the appropriate broker cluster according to the configuration provided to the publisher.
The publisher must be able to run in-process inside a long-running thread or a long running co-routine.
It can also be run using a separate daemon which can serve all the processes publishing to the message brokers.
Messages Backlog¶
The messages backlog is a temporary queue of messages yet to be published to the appropriate broker cluster.
In the event where messages cannot be published for any reason, the messages are kept inside the queue.
By default, an in-memory queue will be used. The user may provide another implementation which stores the messages on-disk or in a central database.
Implementers should take into account what happens whenever writing to the messages backlog fails.
The default fallback mechanism will append the messages into an in-memory queue. These messages will be published first in order to avoid Message loss in case the publisher goes down for any reason.
Publisher Daemon¶
In sufficiently large deployments, one server runs multiple workloads which may publish to a Message Broker.
Therefore, it is unnecessary to maintain a publisher for each process that publishes to a Message Broker.
In such cases, a Publisher Daemon can be used. The publishing processes will specify it as their target and communicate the messages to be published via a socket.
Publisher Internal Services¶
The Publisher defines internal services to ensure it’s operation and to provide support for it’s features.
The exact API for each service will be determined in another CEP.
This list of internal services is not final. Other internal services may be defined in other CEPs.
Message Publisher¶
The Message Publisher service is responsible for publishing
messages to a single Message Broker.
This service is run for each Message Broker the user configured the Publisher to publish messages to.
During the service’s initialization it initializes a Messages Backlog. This will be the backlog the service consumes messages from.
The service maintains a connection pool to the Message Broker and is responsible for scaling the pool according to the pressure on the broker.
The connection pool’s limits are configurable by the user. By default, we only maintain one connection to the Message Broker.
Listener¶
The Listener service is responsible for receiving messages and enqueuing
them in the appropriate Messages Backlog.
During initialization the service starts listening to incoming TCP connections.
The service is only run in case the user opts to run the Publisher in Publisher Daemon mode.
Publisher Health Checks¶
The Publisher will perform health checks to ensure that the Message Broker the user is publishing to is available.
If a health check fails a configured number of times, the relevant Circuit Breaker is tripped.
Each Message Broker Celery supports must provide an implementation for the default health checks the Publisher will use for verifying its availability for new messages.
Further health checks can be defined by the user. These health checks allows the user to avoid publishing tasks if for example a 3rd party API endpoint is not available or slow, if the database the user stores the results in is available or any other check for that matter.
Publisher Circuit Breakers¶
Each health check has it’s own Circuit Breaker. Once a circuit breaker is tripped, the messages are stored in the Messages Backlog until the health check recovers and the circuit is once again closed.
Router¶
The Router is a Message Dispatcher. It is responsible for managing the connection to a Message Broker and consuming messages from the Message Broker.
The Router can maintain a connection to a cluster of message brokers or even clusters of message brokers.
Data Sources and Sinks¶
Data Sources are a new concept in Celery. Data Sinks are a concept which replaces Result Backends.
Data Sinks consume Document Messages while Data Sources produce them.
Data Sources¶
Data Sources are task which either listen or poll for incoming data from a data source such as a database, a file system or an HTTP(S) endpoint.
These services produce Document Messages.
Tasks which are subscribed to Data Sources will receive the raw document messages for further processing.
Example
We’d like to design a feature which locks Github issues immediately after they are closed.
Github uses Webhooks to notify us when an issue is closed.
We set up a Data Source which starts an HTTPS server and expects incoming HTTP requests on an endpoint.
Whenever a request arrives a Document Message is published.
Data Sinks¶
A result from a task produces a Document Message which a Data Sink or multiple Data Sinks consume.
These Document Messages are then stored in the Sinks the task is registered to.
Example
We have a task which calculates the hourly average impressions of a user’s post over a period of time.
The BI team requires the data to be inserted to BigQuery because it uses it to research the effectiveness of users posts.
However, the user-facing post analytics dashboard also requires this data and the team that maintains it doesn’t want to use BigQuery because it is not a cost-effective solution and because they already use MongoDB to store all user-facing analytics data.
To resolve the issue we declare that the task routes it’s results to two data sinks. One for the BI team and the other for the analytics team.
Each data sink is configured to insert the data to a specific table or collection.
Controller¶
The Controller is responsible for managing the lifecycle of all other Celery components.
Celery 5 is a more complex system with multiple components and will often be deployed in high throughput, highly available production systems.
The introduction of multiple components require us to have another component that manages the entire Celery cluster.
During the lifecycle of a worker the Controller also manages and optimizes the execution of tasks to ensure we maximize the utilization of all our resources and to prevent expected errors.
Note
The Controller is meant to be run as a user service. If the Controller is run with root privileges, a log message with the warning level will be emitted.
Foreman¶
The Foreman service is responsible for spawning the Workers, Routers and Schedulers.
By default, the Foreman service creates sub-processes for all the required components. This is suitable for small scale deployments.
Development Mode¶
During development, if explicitly specified, the Foremen will start all of Celery’s services in the same process.
Since some of the new features in Celery require cryptographically signed messages Celery will generate self-signed certificates using the trustme library unless certificates are already provided or the user has chosen to disable this behavior through a CLI option.
SystemD Integration¶
Unless it is explicitly overridden by the configuration, whenever the Controller is run as a SystemD service, it will use SystemD to spawn all other Celery components.
Celery will provide the required services for such a deployment.
The Controller will use the sd_notify protocol to announce when the cluster is fully operational.
The user must configure the list of hosts the controller will manage and ensure SSH communication between the Controller’s host and the other hosts is possible.
Other Integrations¶
Celery may be run in Kubernetes, Swarm, Mesos, Nomad or any other container scheduler.
Users may provide their own integrations with the Foreman which allows them to create and manage the different Celery components in a way that is native to the container scheduler.
The Controller may also manage the lifecycle of the Message Broker if the user wishes to do so.
Such an integration may be provided by the user as well.
Scheduler¶
The scheduler is responsible for managing the scheduling of tasks for execution on a cluster of workers.
The scheduler calculates the amount of tasks to be executed in any given time in order to make cluster wide decisions when autoscaling workers or increasing concurrency for an existing worker.
The scheduler is aware when tasks should no longer be executed due to manual intervention or a circuit breaker trip. To do so, it commands the router to avoid consuming the task or rejecting it.
Concurrency Limitations¶
Not all Tasks are born equal. Some tasks require more resources than others, some may only be executed once at a time due to a business requirement, other tasks may be executed only once per user at a time to avoid data corruption. At times, some tasks should not be executed at all.
The Scheduler is responsible for limiting the concurrency of such tasks.
A task’s concurrency may be limited per worker or globally across all workers depending on the requirements. In case there are tasks which are limited globally, an external data store is required.
If a task is rate limited any concurrency limitations are ignored.
There are multiple types of limits the user can impose on a task’s concurrency:
Fixed Limit: A task can only be run at a maximum concurrency of a fixed number. This strategy is used when there is a predetermined limit on the number of concurrent tasks of the same type either because of lack of computing resources or due to business requirements.
Range: A task can only be run at a maximum concurrency of a calculated limit between a range of numbers. This strategy is used to calculate the appropriate concurrency for a task based on some external resource such as the number of available database connections or currently available network bandwidth.
Concurrency Token: A task can only be run at a maximum concurrency of either a Fixed Limit or a Range if it has the same Concurrency Token. A Concurrency Token is an identifier constructed from the task’s Message by which we group a number of tasks for the purpose of limiting their concurrency. This strategy is used when the user would like to run one concurrent task per user or when a task may connect to multiple database instances in the cluster and the user wishes to limit the concurrency of the task per the available database connections in the selected instance.
A concurrency limitation of 0 implies that the task will be rejected and the queue it is on will not be consumed if possible.
The Scheduler may impose a concurrency limit if it deems fit at any time, these limits take precedence over any user imposed limit.
Suspend/Resume Tasks¶
Whenever a Circuit Breaker trips, the Router must issue an event to the Scheduler. The exact payload of the suspension event will be determined in another CEP.
This will notify the Scheduler that it no longer has to take this task into account when calculating the Celery workers cluster capacity. In addition this will set the task’s concurrency limitation to 0.
The user may elect to send this event directly to the Scheduler if suspension of execution is required (E.g. The task interacts with a database which is going under expected maintenance).
Once scheduling can be resumed, the Scheduler sends another event to the Router. The exact payload of the resumption event will be determined in another CEP.
Task Prioritization¶
The Scheduler may instruct workers to prioritize tasks and to prefer consuming from specific queues first.
Priority based queues are only a partial solution to prioritizing tasks. Some Message Brokers don’t support it. Those who do support priority based queues do not prioritize messages between queues.
This feature can be used to prefer to execute tasks which can be quickly executed first or to execute tasks which take a long time to complete first or to execute tasks which are rarely seen first.
Users may supply their own strategies for prioritizing tasks.
Resource Saturation¶
Celery provides the Resource Saturation Task Prioritization strategy to ensure we can utilize the full capacity of all the workers in the cluster.
The scheduler instructs each worker to prefer executing I/O Bound Tasks if the capacity of the worker for executing CPU Bound Tasks is nearing its maximum and vice versa.
Rate Limiting¶
A user may impose a rate limit on the execution of a task.
For example, we only want to run 200 send_welcome_email() Tasks per minute in order to avoid decreasing our email reputation.
Tasks may define a global rate limit or a per worker rate limit.
Whenever a task reaches it’s rate limit, an event is published to the Router’s Inbox Queue. The event notifies the Router that it should not consume these tasks if possible. The exact payload of the rate limiting event will be determined in another CEP.
In addition the task is suspended until the rate limiting period is over.
Periodic Tasks¶
Previously, Celery used it’s in-house periodic tasks scheduler which was the source of many bugs.
In Celery 5 we will use the APScheduler.
APScheduler has proved itself in production, is flexible and customizable and will provide trio support in 4.0, it’s next major version.
In addition, APScheduler 4.0 will be highly available, a highly demanded feature from our users. This means that two Controller instances may exist simultaneously without duplicated Tasks being scheduled for execution.
The Scheduler only uses APScheduler to publish Tasks at the appropriate time according to the schedule provided by the user. Periodic tasks do not run inside the Scheduler.
Autoscaler¶
The Scheduler contains all the data required for making autoscaling decisions.
It is aware of how many tasks will be automatically rejected because they are suspended for any reason.
It is aware of how many Periodic Tasks are going to be scheduled in the future.
The Scheduler is aware for the maximum concurrency allowed for each worker and the Concurrency Limitations of specific tasks.
The Scheduler also periodically samples the queues’ length.
Unfortunately, modeling such a queuing system is beyond the scope of Celery 5 due to the already large amount of new feature and changes in this version and our lack of knowledge in the math involved in such a model.
Instead we’re going to provide the simple algorithm we use now in Celery 4 with some adjustments but allow room for extension.
In Celery 4 each worker checks if it should autoscale every second. This can cause a lot of thrashing as new processes are created and destroyed.
In Celery 5 after each autoscale event, there will be a cooldown period. The cooldown period increases exponentially until a configurable limit.
If the number of tasks in all the queues is larger than the current concurrency budget the Autoscaler publishes an event to all the routers. The routers will increase their prefetching multiplier as a response to this event.
The Scheduler will select which workers should increase their prefetching of tasks in order to reach the maximal concurrency budget.
Controller Internal Services¶
Motivation¶
Rationale¶
Backwards Compatibility¶
Reference Implementation¶
This document describes the high level architecture of Celery 5. As such, it does not have an implementation at the time of writing.
Copyright¶
This document has been placed in the public domain per the Creative Commons CC0 1.0 Universal license (https://creativecommons.org/publicdomain/zero/1.0/deed).