CEP XXXX: Celery NextGen High Level Architecture¶
- CEP
XXXX
- Author
Omer Katz
- Implementation Team
Omer Katz
- Shepherd
Omer Katz
- Status
Draft
- Type
Informational
- Created
2020-05-27
- Last-Modified
2020-05-27
Table of Contents
Abstract¶
When Celery was conceived, production environments were radically different from today.
Nowadays most applications are (or often should be):
Deployed to a cloud provider’s computing resources.
Distributed (sometimes between data centers).
Available or Consistent (If we store state, we must pick one according to CAP Theorem).
Built with scalability in mind.
Cloud Native - The application’s lifecycle is managed using Kubernetes, Swarm, or any other scheduler.
Heterogeneous - Microservices may be written in different languages.
Also, Celery lacks proper support for large scale deployments and some useful messaging architectural patterns.
Celery 5 is the next major version of Celery, and so we can break backward compatibility, even in significant ways.
As such, our next major version should represent the beginning of a paradigm shift in the way we implement our task execution platform. Future major versions will drastically change how Celery works.
This document provides a high-level overview of the new architecture for the next generation of Celery major versions.
Specification¶
Note
From now on when we write Celery we refer to Celery NextGen.
Whenever we refer to a previous major version of Celery we will specify the version number.
Diagram¶
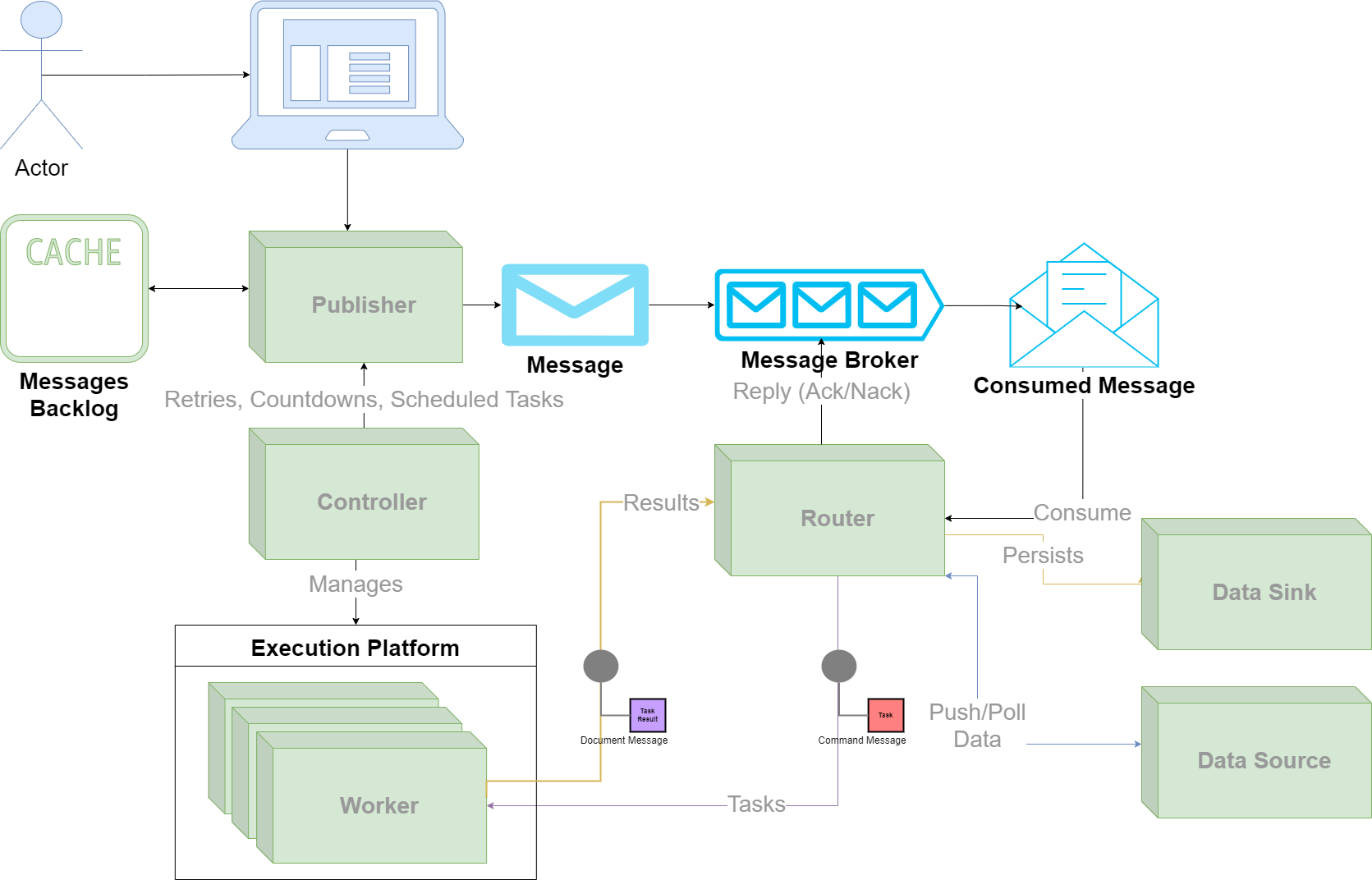
High Level Architecture Diagram¶
Preface¶
In Celery 4.x we had the following architectural building blocks:
In addition we had a few optional architectural building blocks (some of them maintained by the community):
The only architectural building blocks that remain in Celery are the Python Runtime and the Message Broker. The rest are replaced by new ones which provide more functionality and flexibility for our users.
In the rest of this specification we will describe the architectural building blocks of Celery.
Python Runtime¶
Python 2 no longer receives support and security patches from the community as of January 1st, 2020. Therefore, Celery will drop support for Python 2 and will run on Python 3 and above.
Celery supports the CPython and PyPy Python runtimes. Other runtimes will be considered in different CEPs on a case-by-case basis.
As a general guideline, we will attempt to keep support for the latest Python version PyPy supports. However, if the need arises we will opt to use new Python language features and hope PyPy can catch up.
Message Types¶
In Celery 4.x we only have tasks which are serialized to Command Messages that we publish to the Message Broker whenever we want to execute a Task.
Document messages are the messages we got as a result. Those message were stored in the Result Backend. They had a specific format which only the Celery 4.x library knew how to parse.
In Celery, we now have new types of messages we can use.
Document Messages may now also be produced whenever we publish a serialized representation of a Domain Model to the Message Broker. These messages may be received from a Data Source or published directly from the application.
Event Messages are a new concept for Celery. They describe that a Domain Event occurred. Multiple tasks can subscribe to an event. Whenever we receive an Event Message we publish those tasks as Command Messages to the Message Broker.
These fundamental architectural building blocks will aid us in creating a better messaging system. To encourage Ubiquitous Language, we will be using them in this document when applicable and in Celery’s codebase as well.
Message Broker¶
In Celery 4.x each Celery Master connected to only one Message Broker cluster.
This is no longer the case. Celery now allows connecting to multiple Message Brokers even if they are of clusters that use different implementations of a message broker.
Users can consume messages from a Redis cluster, a RabbitMQ cluster, and an ActiveMQ cluster if they so desire.
This feature is useful when, for example:
The user migrates from a legacy system that uses other implementation of a Message Broker, but the new system uses a more modern one.
The user wants to split the load between clusters.
There’s a security reason to publish some messages to a specific cluster.
On some Message Broker implementations the Controller will assist in managing the cluster.
Data Sources & Sinks¶
In Celery 4.x we had a Result Backend which was used to store task results and coordinate the execution of chords.
We extend the Result Backend concept further to allow new use cases such:
ETL.
Reporting.
Taking action when data is inserted or updated.
In addition, like we did for the Message Broker, we now allow multiple data sources and sinks instead of one cluster of a Result Backend.
The responsibility for coordination of the execution of chords has moved to the Execution Platform.
Data Sinks¶
A data sink is where task results are saved.
A task result may be saved in more than one data sink (e.g. a Kafka Topic and S3).
The Router is responsible for routing task results to the correct data sink(s) and properly serializing them.
Data Sources¶
A data source is a anything that stores data. It can be a Kafka topic, a S3 bucket, a RDBMS or even your local filesystem.
Some data sources can notify Celery of incoming data. Others, Celery needs to poll periodically using the Task Scheduler.
The Router is responsible for listening to incoming data from the various data sources connected to it.
Whenever the Router receives incoming data it sends a Document Message to the Publisher which in turn will publish it to the Message Broker.
Controller¶
In Celery 4.x we provided a basic tool for controlling Celery instances called Celery Multi. We also provided Celery Beat for periodically scheduling tasks.
The Controller replaces those two components and extends their functionality in many ways.
The Controller is responsible for managing the lifecycle of all other Celery components.
Celery is a complex system with multiple components and will often be deployed in high throughput, highly available, cloud-native production systems.
The introduction of multiple components require us to have another component that manages the entire Celery cluster.
Instead of controlling Celery instances on one machine in a way that is agnostic to the production environment we’re operating in the Controller now provides a Platform Manager which manages Celery instances on one or many machines.
The Controller also manages and optimizes the execution of tasks to ensure we maximize the utilization of all our resources and to prevent expected errors.
That is why the Controller is now responsible for auto-scaling Celery instances, rate-limiting tasks, task concurrency limitations, task execution prioritization and all other management operations a user needs to operate a Celery cluster.
Platform Manager¶
The Platform Manager is responsible for interacting with the production environment.
The platform itself can be anything Celery can run on e.g.: Pre-fork, SystemD, OpenRC, Docker, Swarm, Kubernetes, Nomad.
Each implementation of the Platform Manager will be provided in a different package. Some of them will be maintained by the community.
Foreman¶
The Foreman is responsible for deploying & managing the lifecycle of all Celery instances and ensuring they stay up and running.
It can spawn new instances of Celery processes, stop or restart them either on demand or based on policies the user has specified for auto-scaling.
It interacts with the Platform Manager to do so on the platform the Controller manages.
On some platforms, the Foreman can instruct the Platform Manager to deploy and manage the lifecycle of Message Brokers, Data Sources & Data Sinks.
Task Scheduler¶
The Task Scheduler is responsible for managing the scheduling of tasks for execution on a cluster of workers.
The scheduler calculates the amount of tasks to be executed in any given time in order to make cluster wide decisions when autoscaling workers or increasing concurrency for an existing worker.
The scheduler is aware when tasks should no longer be executed for any reason. To do so, it commands the router to avoid consuming the task or rejecting it.
Publisher¶
The Publisher is responsible for publishing Messages to a Message Broker.
It is responsible for publishing a Message to the appropriate Message Broker cluster according to the configuration provided to the publisher.
The publisher must be able to run in-process inside a long-running thread or a long running co-routine.
It can also be run using a separate daemon which can serve all the processes publishing to the message brokers.
Whenever the Message Broker cluster is unavailable or unresponsive, the Publisher stores the Messages in the Messages Backlog. The Publisher will later retry publishing the message.
Router¶
In Celery 4.x there was a Celery Master which was responsible for consuming Messages, storing results and executing canvases.
In Celery we now decouple the execution of the tasks completely from the routing of Messages to the Execution Platform.
The Router is a combination of the following architectural patterns: - Event Driven Consumer - Message Dispatcher - Service Activator - Process Manager.
The Router consumes Messages from a Message Broker cluster or multiple clusters, dispatches the consumed Messages to the Execution Platform for processing and awaits for the results of the task and stores them in the appropriate Data Sink(s).
When the execution of a task requires coordination in case of a workflow, an Event Message or an incoming Document Message from a Data Source the Router is responsible for the order of the execution of the task(s).
Execution Platform¶
In Celery 4.x we had Celery Worker which was responsible for executing tasks.
In Celery we now have an execution platform which will execute tasks and report their results back to the Router.
Celery will provide a default implementation but other implementations may be provided as well by the community or the maintainers.
Alternative implementations may provide task execution on Serverless Computing platforms, as Kubernetes Jobs for example or provide task execution for tasks written in a different language.
Motivation¶
We want to modernize Celery for the Cloud Native age. We need to keep Celery relevant for our users and help them in new ways. Therefore, we must adjust and evolve to meet the unique challenges of the Cloud Native age.
Also, we want to modernize the code to support Python 3+, which will allow us to remove workarounds, backports, and compatibility shims. Refactoring the codebase to support Python 3+ allows us to keep a slimmer, more maintainable codebase.
Furthermore, we’d like to resolve long-standing design bugs in our implementation.
Gradually evolving our codebase is currently not possible due to the many changes in technology since Celery was conceived. We need to move fast and break things until we match all our goals.
Rationale¶
This architecture moves Celery from the past to the present.
We have the following goals:
Observability
Cloud Nativity
Flexibility
Increased Task Completion Throughput
The proposed architecture will guarantee that those goals will be met.
Backwards Compatibility¶
As evident from this document, Celery NextGen is not backwards compatible with previous versions of Celery.
The syntax for defining tasks will remain the same so you can reuse your code with little to no adjustments.
Reference Implementation¶
Copyright¶
This document has been placed in the public domain per the Creative Commons CC0 1.0 Universal license (https://creativecommons.org/publicdomain/zero/1.0/deed).